Apart Research AI Safety Hackathon — asia-fertility
A recap of the Apart Research AI Safety Hackathon that turned into a measured indictment of how LLM tokenizers price Asian languages. What shipped, what it costs users, how to run the benchmark on your own stack in two minutes, and who actually pays.
Your LLM tokenizer is silently charging Tamil users 7.6× English rates. Burmese users pay 11.66×. Same content, same model, before the model even runs.
That is the finding I walked out of the Apart Research Global South AIs Hackathon with. This piece is the recap: the experience, the results, what shipped, how to run the benchmark on your own stack, and the social layer the technical work is actually about.
A minute on the terms
Before the findings, three words this piece leans on.
A tokenizer is the very first thing that happens to your prompt. Before the model reads a single word, the tokenizer chops your text into small subword pieces called tokens — that is what the model actually sees. Every commercial LLM API bills per token, measures its context window in tokens, and enforces rate limits in tokens. The tokenizer is a preprocessing step, but it prices everything downstream.
Fertility is the technical name for how many tokens a tokenizer produces per word (or per sentence) of a given language. High fertility means the tokenizer chops that language into many small pieces; low fertility means it packs meaning densely. English tokenizers were trained on mostly English text, so they have low fertility on English and high fertility on languages they saw less of — which is where the "tax" comes from.
NIAH (needle in a haystack) is the standard test for whether a model can actually retrieve information from a long context: you drop a marker phrase somewhere inside a long block of text, ask the model to recall it, and score whether it comes back correctly. It measures retrieval reliability, not just how large the context window claims to be.
With those three, the rest of the piece reads as one continuous argument: the tokenizer sets the fertility, fertility sets the cost and the effective window, and NIAH measures whether the window is actually usable in the target script.
What I found
Three benchmarks. Three findings.
1. Cost ratio — the API bill
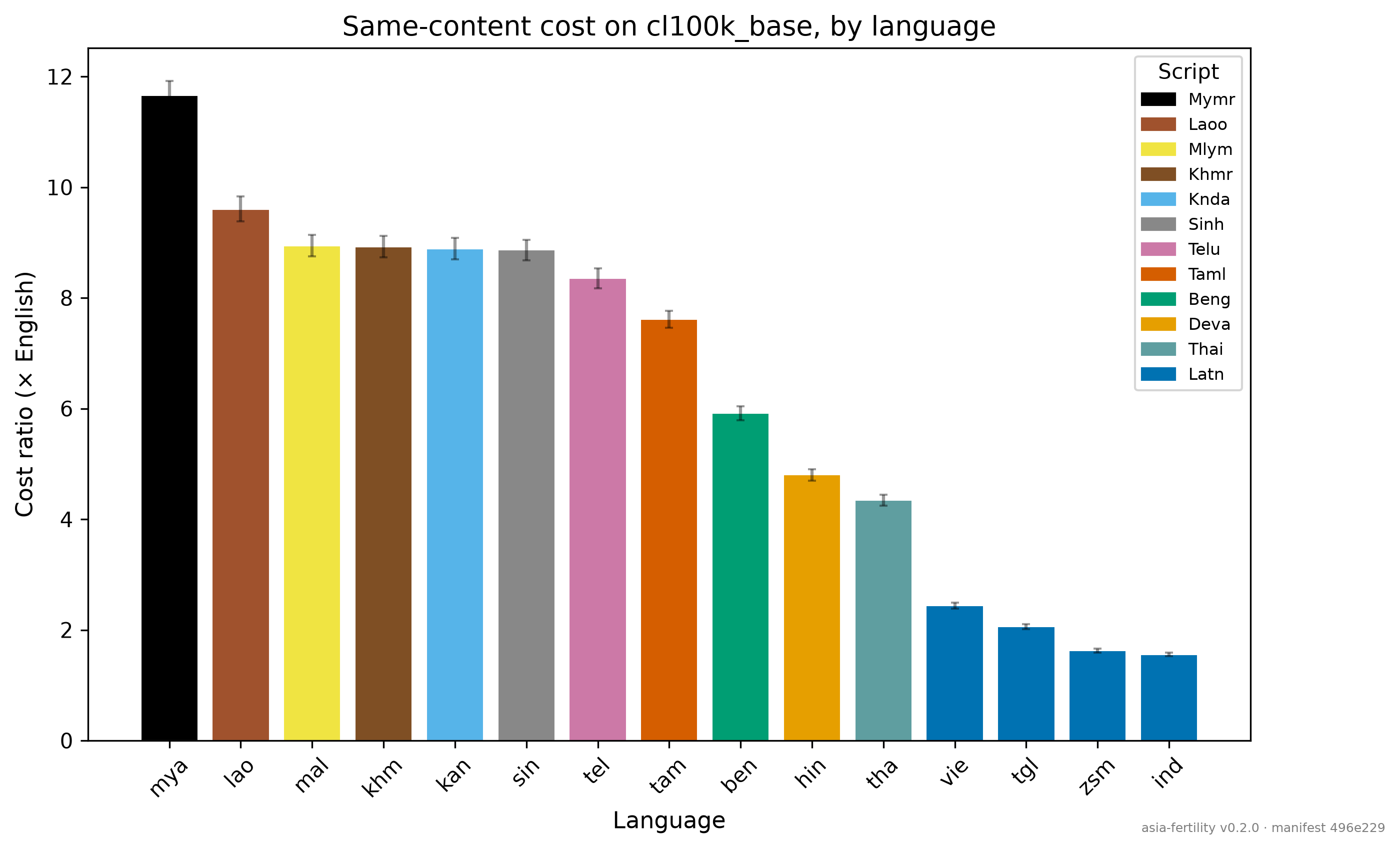
Median cost multiplier for the 11 non-Latin scripts on OpenAI's cl100k_base (GPT-3.5, GPT-4 Turbo): 8.9×. Burmese pays 11.66×. Lao 9.60×. Malayalam 8.94×. Same content, in FLORES-200 parallel translation. The ratio is 100% attributable to the tokenizer.
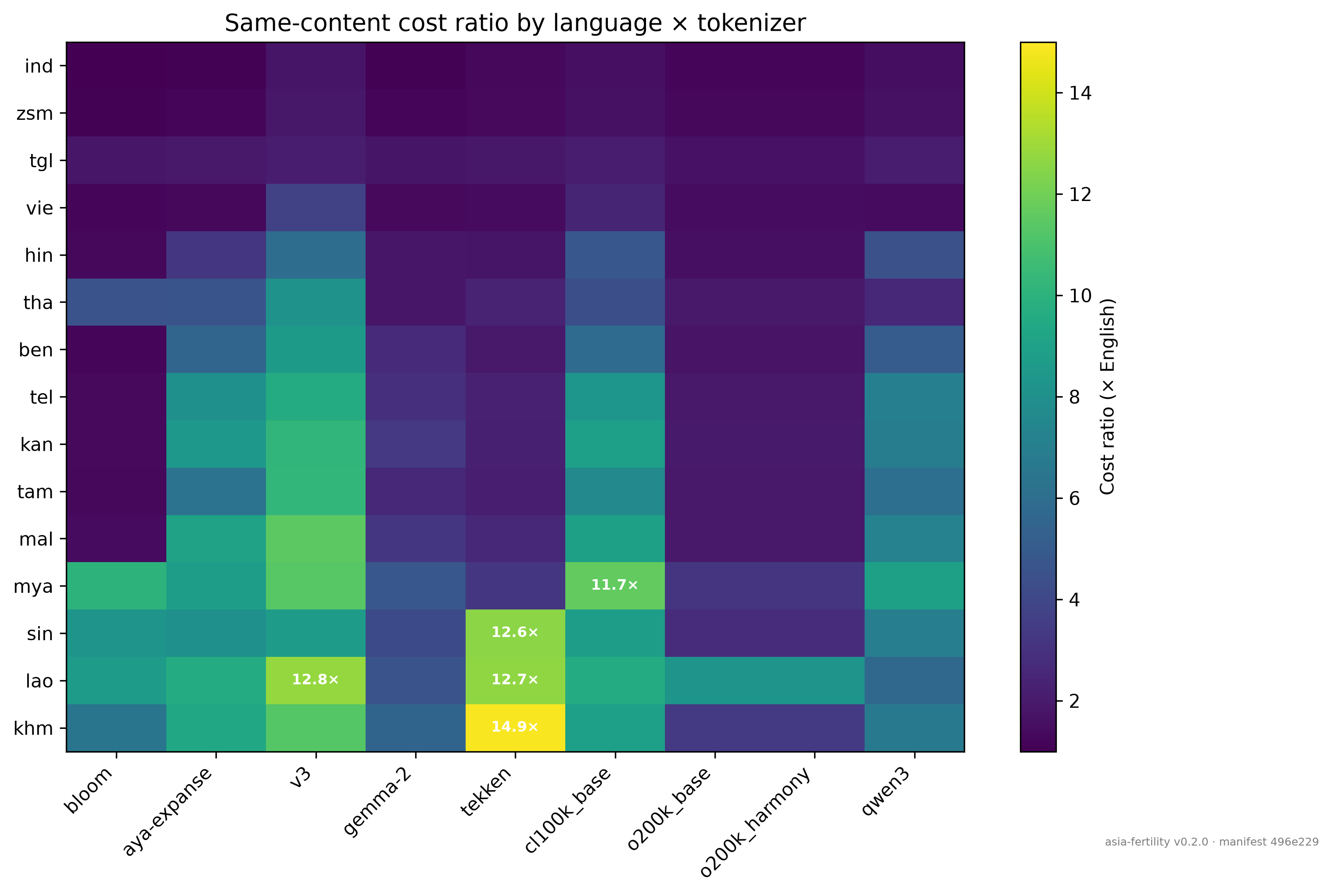
The most useful surprise is how much of the tax is fixable by choosing the tokenizer, not by fine-tuning. Switching Tamil from cl100k_base to o200k_base (GPT-4o, GPT-5) cuts the cost from 7.61× to 1.98×. Burmese drops from 11.66× to 3.18×. Malayalam from 8.94× to 1.95×. One dropdown.
2. NIAH recall — can the model retrieve script-native content?
I ran a 4,000-cell needle-in-a-haystack grid: 16 languages × 5 frontier OpenRouter models × 5 fill levels × 5 marker positions × 2 trials. Every haystack script got its own semantically-parallel marker (Tamil குறி-உதயம்-924, Devanagari चिन्ह-उषाकाल-924, Burmese အမှတ်-အရုဏ်ဦး-924, and so on — all meaning "mark-dawn-924").
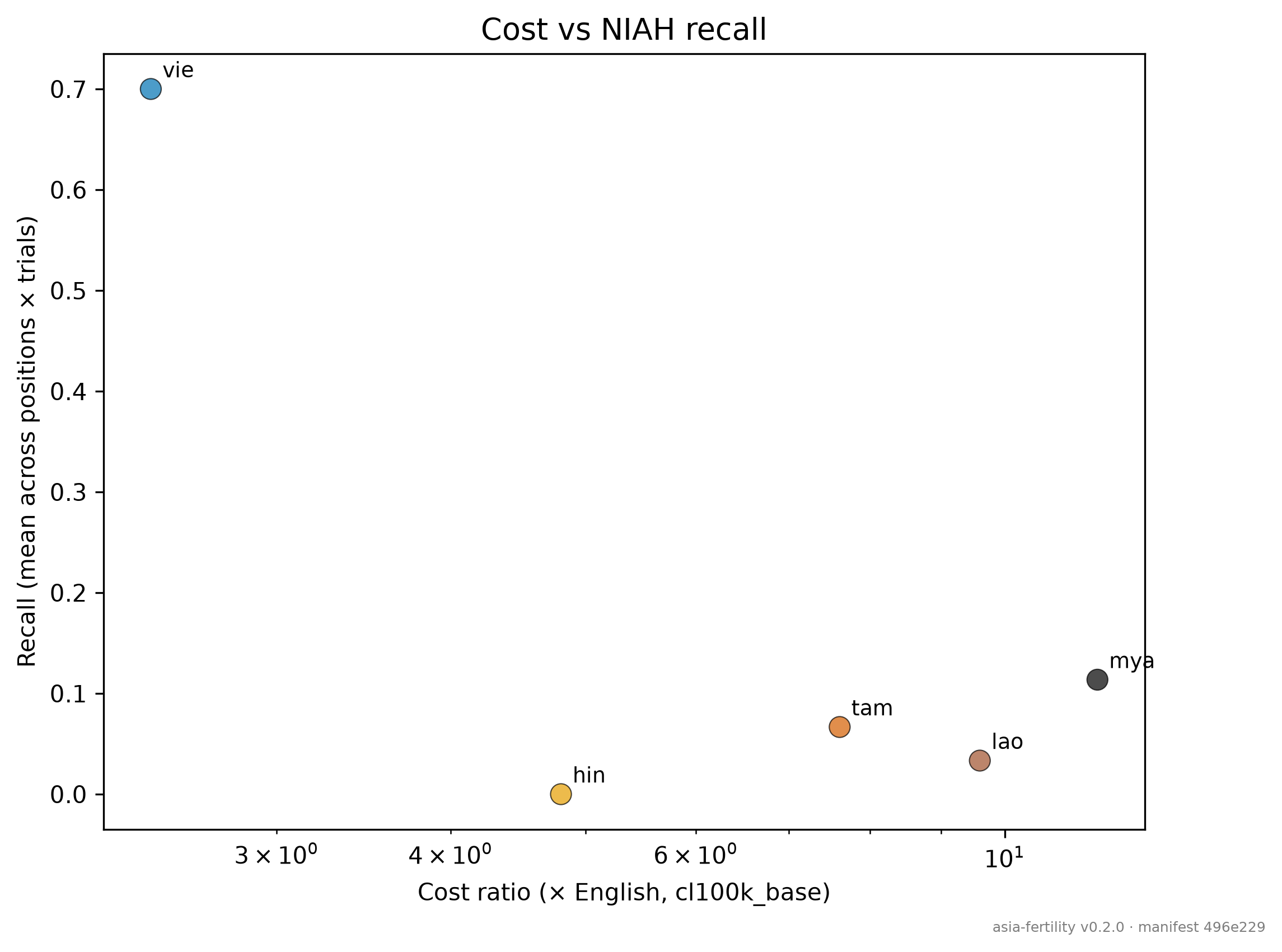
Four of five frontier models collapse to 0–2 out of 10 recall on non-Latin Asian languages already at 4k tokens — well inside every model's advertised context window. This is not "lost in the middle" — it's script-representation failure that shows up at every measured depth.
But gemini-2.5-flash retains 84.5% pooled recall on the same grid. One vendor's training choice separates 84% from 15–36%. The collapse is not intrinsic to the task; it's a vendor-level decision.
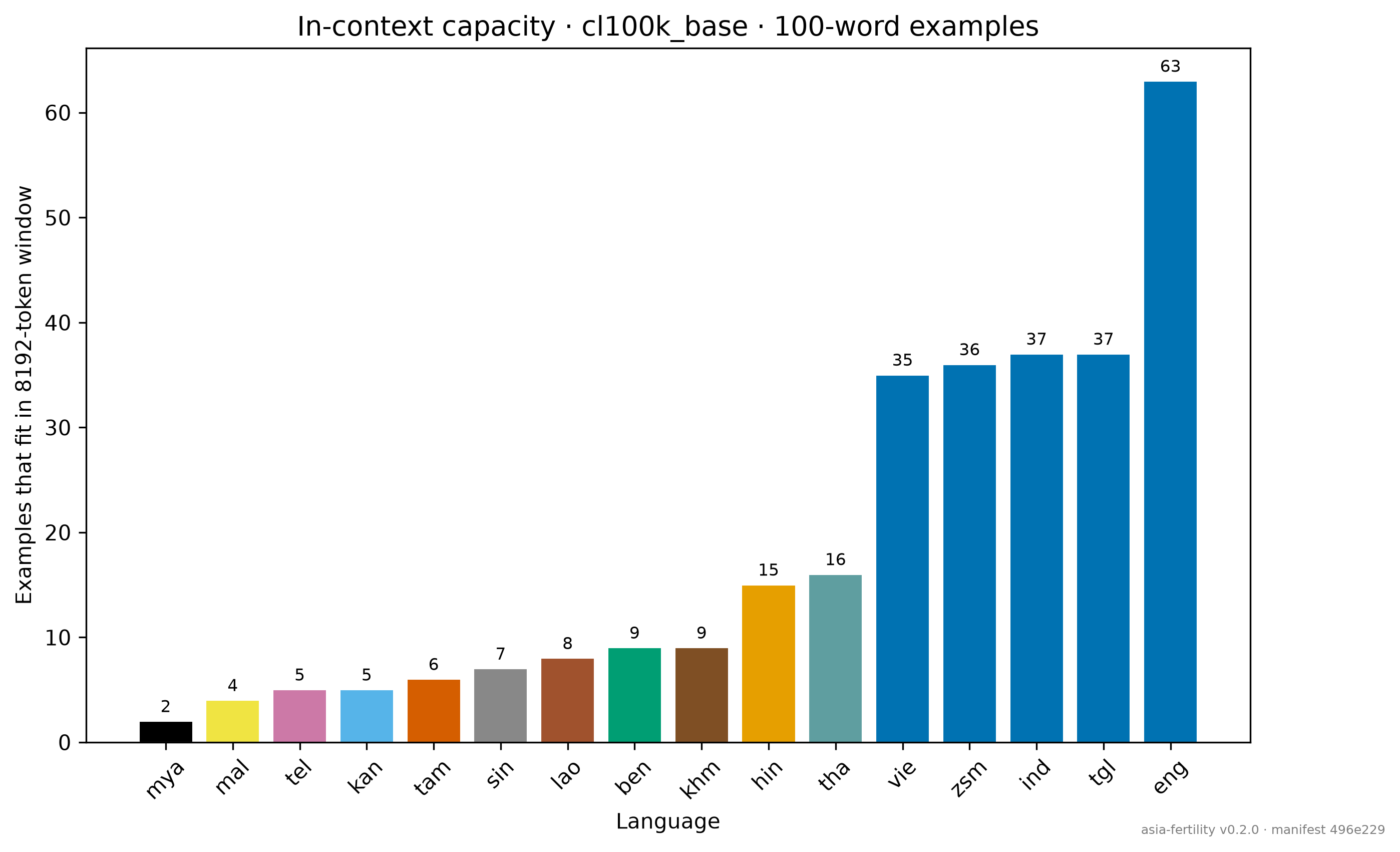
Bonus finding: "effective context window" is language-dependent. deepseek-chat-v3-0324 recalls cleanly at 131k on Latin scripts but errors HTTP 400 on 100% of non-Latin haystacks at the same notional size — because 131k of o200k_base expands to 600k+ tokens in DeepSeek's native BPE for Brahmic scripts, overflowing the window before inference.
3. Latency — does the cost penalty reach the user?
Pooled Pearson r between cost ratio and wall-clock ratio: 0.314 across 5 models × 16 languages × 10 measured trials. Not the 0.94 the earlier African-language study reported.
Reading of the data: modern 2026 serving stacks (continuous batching, prefill parallelism, dynamic routing) absorb most of the input-side fertility penalty before it reaches wall-clock. A CFO watching cost sees 11× pain on Burmese; a user watching wall-clock sees roughly 1.5× on average. Different problems, different mitigations.
What ships
Three open, cross-linked artefacts. All permanently addressable.
- Package (PyPI + GitHub) —
pip install asia-fertility[oai]. CLI + Python API, 10 tokenizers, 16 languages, 6 paper figures, deterministic offline reproduce. MIT license. → github.com/Helmo21/asia-fertility - Dataset (HuggingFace) — three configs:
leaderboard(160 rows),niah(4,000 rows),latency(1,040 rows). Every version subfolder ships amanifest.json. CC-BY-SA 4.0. → huggingface.co/datasets/Helmo21/asia-fertility - Paper (Zenodo preprint) — 15 pages, three benchmarks, three findings, 8 figures. CC-BY 4.0. Permanent DOI: 10.5281/zenodo.21069313
How to use the package
Two-minute smoke test, offline, no API keys:
pip install "asia-fertility[oai]"
asia-fertility reproduce
That runs a bundled 10-sentence × 16-language reference suite in about three seconds — enough to verify the install matches the paper's methodology.
Real usage. Measure a specific corpus on a specific tokenizer:
asia-fertility measure --text "your text here" --tokenizer cl100k_base
asia-fertility cost --text "your text here" --model gpt-4o
asia-fertility tokenizers list
asia-fertility languages list
Reproduce the leaderboard from scratch:
asia-fertility run --config configs/main.yaml
asia-fertility figures --run runs/main
asia-fertility leaderboard --run runs/main
Run the full NIAH grid (this one costs real money on OpenRouter):
export OPENROUTER_API_KEY=...
asia-fertility niah run --config configs/niah_main.yaml
asia-fertility niah report --run runs/niah_main
Every run persists a manifest.json with SHA-256s of the config, pinned prices YAML, pinned FX YAML, and exact tokenizer library versions. Given a manifest, anyone can reconstruct the exact environment that produced any figure in the paper.
The social impact
The 16 languages I benchmarked have roughly 1 billion first-language speakers between them. Tamil, Bengali, Hindi, Telugu, Malayalam, Kannada, Sinhala, Thai, Burmese, Khmer, Lao, Vietnamese, Filipino, Malay, Indonesian.
For all of them, when a company builds an AI product on cl100k_base — still one of the most common tokenizer choices in 2026 — the per-user API bill for a native-language interaction runs somewhere between 1.5× and 11.7× the English baseline. Context windows fill that much faster. Rate limits hit that much sooner. And for the four of five frontier models that collapse on non-Latin scripts at 4k tokens, script-native retrieval is not merely expensive — it simply fails.
The concrete effect: any AI product priced against English-cost economics will underserve, deprioritise, or quietly exclude native-language users at scale. That is not a bug of one model. It is the shape of a preprocessing choice that has been made globally, without measurement, for years.
The tokenizer becomes a procurement decision. Different models have very different ones. That decision determines the API bill, the effective context window, and retrieval reliability for script-native content. The measurement is $0 and two minutes. That is the whole point of the package.
Yong 2023 and Wang 2023 both show cross-lingual jailbreak and harm elicitation on the same low-resource languages that carry the highest tokenizer tax. Suggestive of a shared upstream cause. A script-native safety benchmark is the next thing that needs to exist.
One ask
The preprint is on Zenodo with a permanent DOI, immediately citable. I'd like to also submit to arXiv (cs.CL), which requires an endorsement from an existing arXiv author in the same category. If you're an existing arXiv NLP author and the work looks legitimate to you, I'd be very grateful for an endorsement. Reach me at antoine@helmo-solutions.com.
If you build AI for Asian markets, benchmark before you deploy. pip install asia-fertility and one CLI call gets you there.